相关链接:
模仿“先思考再回答”,提示词工程
前言
2020-2021: GPT-3展示Few-shot能力 ↓问题:直接输出答案,缺少推理过程 ↓2022年1月: Chain-of-Thought提出 ↓核心突破:展示推理步骤,激发模型推理能力 ↓2022-2023: ReAct、Self-RAG等基于CoT爆发 ↓2023: Agent时代,CoT成为标配输入:Q: 一个房间有10个人,又来了5个人,最后走了2个人。房间还剩多少人?A: 13
模型输出(直接):Q: 一个房间有20个人,又来了10个人,最后走了5个人。房间还剩多少人?A: 25(✅ 正确,但碰巧)
Q: 小明有5个苹果,给了小红2个,又吃了1个,还剩几个?A: 3(❌ 错误!应该是2)存在问题:
- 模型直接输出结果,没有推理过程
- 复杂的多步计算容易出错
- 无法纠正中间步骤的错误
引入思维链:
输入:Q: 一个房间有10个人,又来了5个人,最后走了2个人。房间还剩多少人?A: 房间原本有10人。 又来了5人,现在有10+5=15人。 最后走了2人,还剩15-2=13人。 答案是13。
模型输出(思维链):Q: 小明有5个苹果,给了小红2个,又吃了1个,还剩几个?A: 小明原本有5个苹果。 给了小红2个,还剩5-2=3个。 又吃了1个,还剩3-1=2个。 答案是2。(✅ 正确!)作用原理:
- ✅ 展示推理过程,模型学会了”模仿”
- ✅ 分成小步骤,每步更容易正确
- ✅ 错误更容易发现和纠正
效果总结
CoT的能力是”涌现”的,只在足够大的模型中才出现
模型规模 vs CoT效果:
- 小型模型(<100B):CoT效果不明显
- 大型模型(100B-500B):CoT效果显著
- 超大型模型(500B+):CoT效果最佳
Abstract
chain-of-thought prompting 提高LLM执行复杂推理能力

1. Introduction
仅扩大模型规模已被证明不足以在具有挑战性的任务(如算术、常识和符号推理)上取得高性能
- 首先,算术推理技术可以从生成导致最终答案的自然语言基本原理中受益。(中间推理过程?)(微调?)
- 其次,大型语言模型提供了令人兴奋的前景,即通过提示在上下文中进行少量的学习。(few_shot)
思维链提示: ⟨⟨输入, 思维链, 输出⟩⟩
2. 思维链提示 Chain-of-Thought Prompting
具体而言,思维链提示通常由多个中间步骤组成,每个中间步骤都解释了问题的一个方面或子问题。模型需要根据前一个步骤的结果和当前问题的要求来推断下一个步骤。通过这种逐步推理的方式,模型可以逐渐获得更多信息,并在整个推理过程中累积正确的推断。 思维链提示的优势在于它提供了一个结构化的方式来指导模型进行复杂的推理任务。它帮助模型更好地理解问题的逻辑和语义,避免直接从问题到答案的简单映射,而是通过中间步骤的推理逐渐逼近最终答案。
本文的目标是赋予语言模型生成类似思维链的能力——一系列通向问题最终答案的连贯的中间推理步骤。我们将展示足够大的语言模型可以在少样本提示的示例中提供思维链推理演示时生成思维链。
思维链类似于一个解决方案,并且可以这样解释,但我们仍然选择称其为思维链,以更好地捕捉它模仿逐步思维过程得出答案的概念
特性:
- 分解问题,将多步骤问题分解为中间步骤
- 解释模型行为,表明他如何得到答案,为后续调试推理错误路径提供参考
- 思维链推理可用于数学应用题、常识推理和符号操作等任务,并且原则上可能适用于人类可以通过语言解决的任何任务
- 思维链推理可以很容易地在足够大的现成语言模型中引出,只需将思维链序列的示例包含到少数提示的示例中。
3. 算数推理 Arithmetic Reasoning
3.1 Experimental Setup
Benchmark
- 数学应用题基准 GSM8K
- 具有不同结构的数学应用题数据集 SVAMP
- 多样化数学应用题数据集 ASDiv
- 代数文字题数据集 AQuA
- MAWPS 基准测试
Standard Prompting
语言模型在输出测试示例的预测之前,会获得输入-输出对的上下文内示例。示例格式为问题和答案。不包括中间过程,模型直接给出答案,如图1(左)所示。
Chain-of-thought prompting
few-shot prompting with a chain of thought for an associated answer由于大多数数据集只有评估集,我们手动编写了一组包含八个思维链的少样本示例用于提示。

Language Models
- GPT-3(Brown等人,2020), text-ada-001, text-babbage-001, text-curie-001 和 text-davinci-002,它们可能对应于 350M, 1.3B, 6.7B 和 175B 参数的 InstructGPT 模型
- LaMDA 422M, 2B, 8B, 68B 和 137B
- PaLM 8B, 62B 和 540B
- UL2 20B
- Codex
3.2 Results
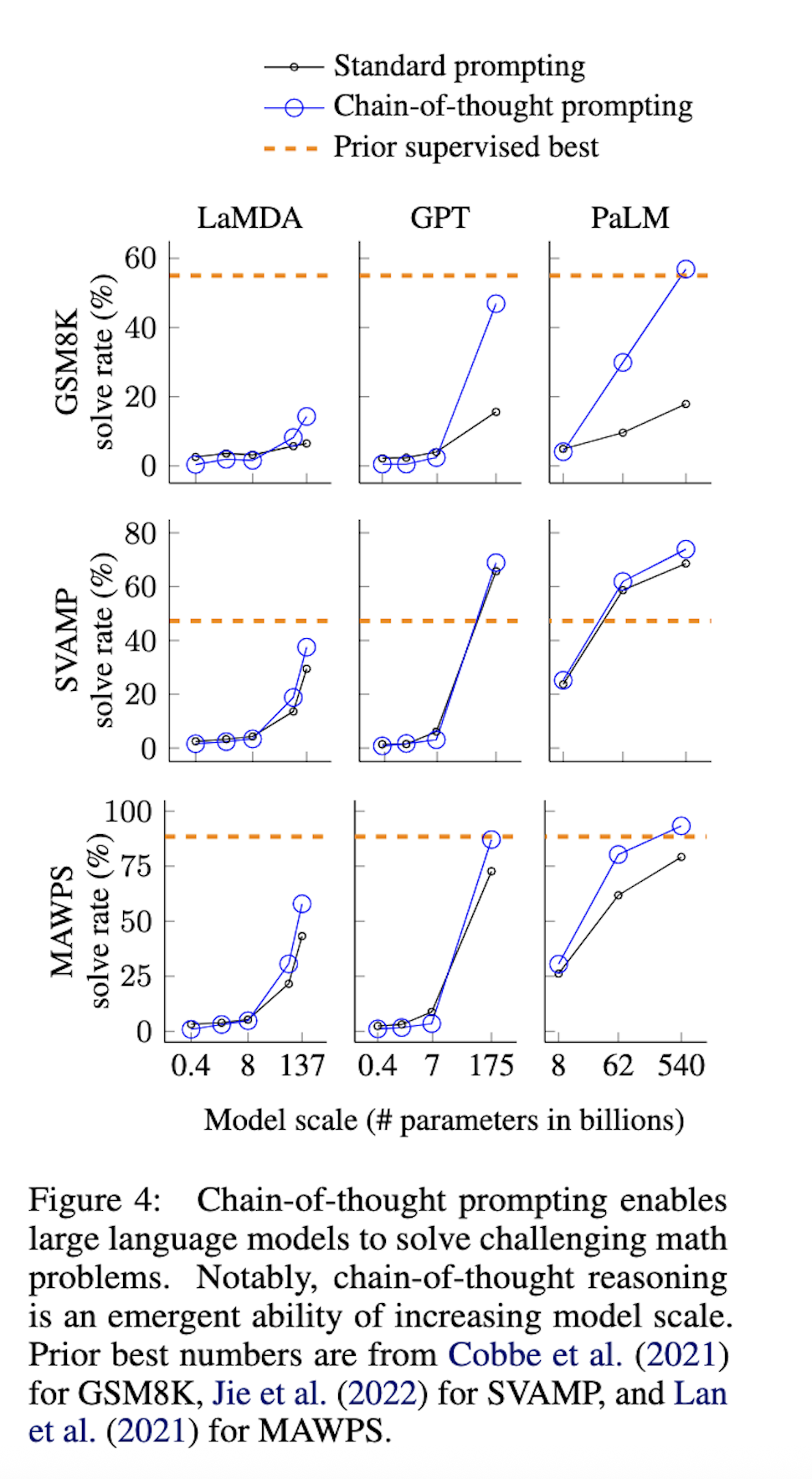
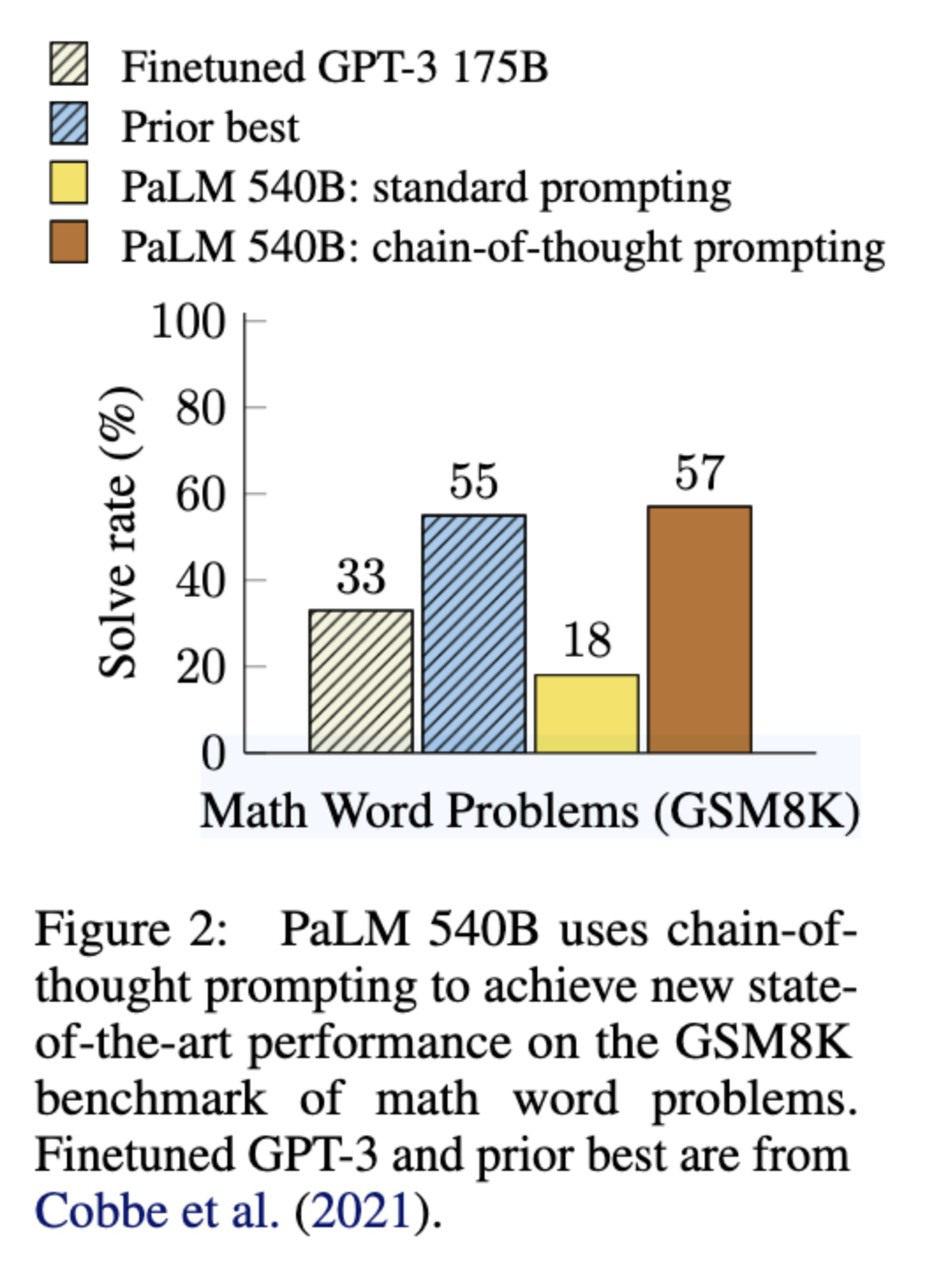
- 思维链提示是模型规模的一种涌现能力。也就是说,思维链提示对小模型的性能没有积极影响,只有与约100B参数的模型一起使用时才会带来性能提升。较小规模的模型会产生流畅但不合逻辑的思维链,导致性能低于标准提示。
- 思维链提示对更复杂的问题有更大的性能提升。例如,对于 GSM8K(基线性能最低的数据集),最大的 GPT 和 PaLM 模型的性能提高了一倍多。另一方面,对于 MAWPS 中最简单的子集 SingleOp(仅需一步即可解决),性能提升为负或非常小
- 通过 GPT-3 175B 和 PaLM 540B 进行的思维链提示与先前的最先进水平相比具有优势,后者通常是在带标签的训练数据集上微调特定任务模型。图4 显示了 PaLM 540B 如何使用思维链提示在 GSM8K、SVAMP 和 MAWPS 上取得新的最先进水平(但请注意,标准提示在 SVAMP 上已经超过了先前最佳)。在另外两个数据集 AQuA 和 ASDiv 上,使用思维链提示的 PaLM 距离最先进水平在 2% 以内
关于涌现能力:
- 小模型上会产生不符合逻辑的思维链,导致表现低于标准的prompt。
- CoT在复杂的问题上有显著的性能提升。
- 在GPT-3和PALM上的CoT超过了微调的SOTA。
总结是,将 PaLM 扩展到 540B 修复了 62B 模型中很大一部分的单步缺失和语义理解错误
3.3 消融实验 Ablation Study
仅方程式 Equation only
模型被提示在给出答案之前仅输出一个数学方程式,如上图所示,仅方程式提示对 GSM8K 没有太大帮助,这意味着 GSM8K 中问题的语义对于在没有思维链中自然语言推理步骤的情况下直接转化为方程式来说过于复杂。然而,对于一步或两步问题的数据集,我们发现仅方程式提示确实提高了性能,因为方程式可以很容易地从问题中推导出来
仅可变计算 Variable compute only
另一种直觉是,思维链允许模型在更难的问题上花费更多的计算(中间标记)。为了将可变计算的效果与思维链推理分离开来,我们测试了一种配置,其中模型被提示仅输出一串点(…),其数量等于解决问题所需方程式的字符数。这个变体的表现与基线大致相同,这表明可变计算本身并不是思维链提示成功的原因,而通过自然语言表达中间步骤似乎是有用的。
答案后的思维链 Chain of thought after answer
思维链提示的另一个潜在好处可能仅仅是这种提示允许模型更好地访问预训练期间获得的相关知识。因此,我们测试了一种替代配置,其中思维链提示仅在答案之后给出,以隔离模型是否真正依赖于生成的思维链来给出最终答案。这个变体的表现与基线大致相同,这表明体现在思维链中的顺序推理之所以有用,不仅仅是由于激活知识的原因。
3.4 Robustness of Chain of Thought
上图显示了在 GSM8K 和 MAWPS 上使用 LaMDA 137B 的这些结果(其他数据集的消融结果见附录表6/表7)。尽管不同思维链标注之间存在差异,正如使用基于示例的提示时所预期的那样(Zhao等人,2021;Min等人,2022),但所有思维链提示集都大幅优于标准基线。这一结果意味着思维链的成功使用并不依赖于特定的语言风格。
4. 常识推理 Commonsense Reasoning
尽管思维链特别适合数学应用题,但思维链基于语言的特性实际上使其适用于广泛的常识推理问题,这些问题涉及在一般背景知识的假设下对物理和人类互动的推理。
Benchmark
- CSQA 提出关于世界的常识性问题,涉及复杂的语义,通常需要先验知识
- StrategyQA 要求模型推断出回答问题的多跳策略
- BIG-bench collaboration - 日期理解,涉及从给定上下文中推断日期
- BIG-bench collaboration - 运动理解,涉及判断与运动相关的句子是否合理
- SayCan 数据集 涉及将自然语言指令映射到离散集中的一系列机器人动作
Prompts
遵循与前一节相同的实验设置。对于 CSQA 和 StrategyQA,我们从训练集中随机选择示例,并手动为它们编写思维链作为少样本示例。两个 BIG-bench 任务没有训练集,因此我们选择评估集中的前十个示例作为少样本示例,并在评估集的其余部分报告数字。对于 SayCan,我们使用了 Ahn等人(2022)中训练集中的六个示例,并同样手动编写了思维链。
Result
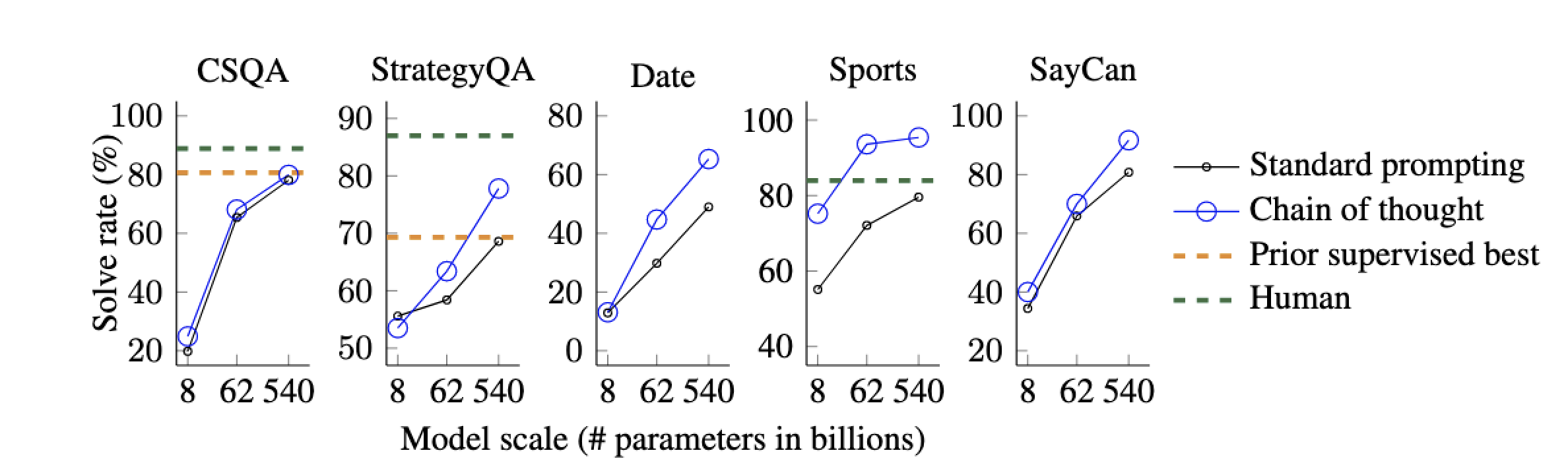
对于所有任务,扩大模型规模提高了标准提示的性能;思维链提示带来了进一步的增益,并且改进似乎在 PaLM 540B 上最大。通过思维链提示,PaLM 540B 相对于基线取得了强劲性能,在 StrategyQA 上超过了先前最先进水平(75.6% vs 69.4%),并在运动理解上超过了未受辅助的运动爱好者(95.4% vs 84%)。这些结果表明,思维链提示也可以提高需要一系列常识推理能力的任务的性能(但请注意,在 CSQA 上的增益很小)。
5. 符号推理 Symbolic Reasoning
思维链提示不仅使语言模型能够执行在标准提示设置下具有挑战性的符号推理任务,而且还促进了长度泛化,使推理时输入的长度超过了少样本示例中所见的长度。
Tasks
- 末字母连接 Last letter concatenation
- 抛硬币Coin flip
由于这些符号推理任务的结构是明确定义的,对于每个任务,我们考虑一个_域内_测试集,其中示例的步骤数与训练/少样本示例相同,以及一个_域外_测试集,其中评估示例的步骤数多于示例中的步骤数。对于末字母连接,模型只看到两个单词的姓名示例,然后对 3 个和 4 个单词的姓名执行末字母连接。我们对抛硬币任务中的潜在翻转次数也做了同样的处理。我们的实验设置使用了与前两节相同的方法和模型。
Result
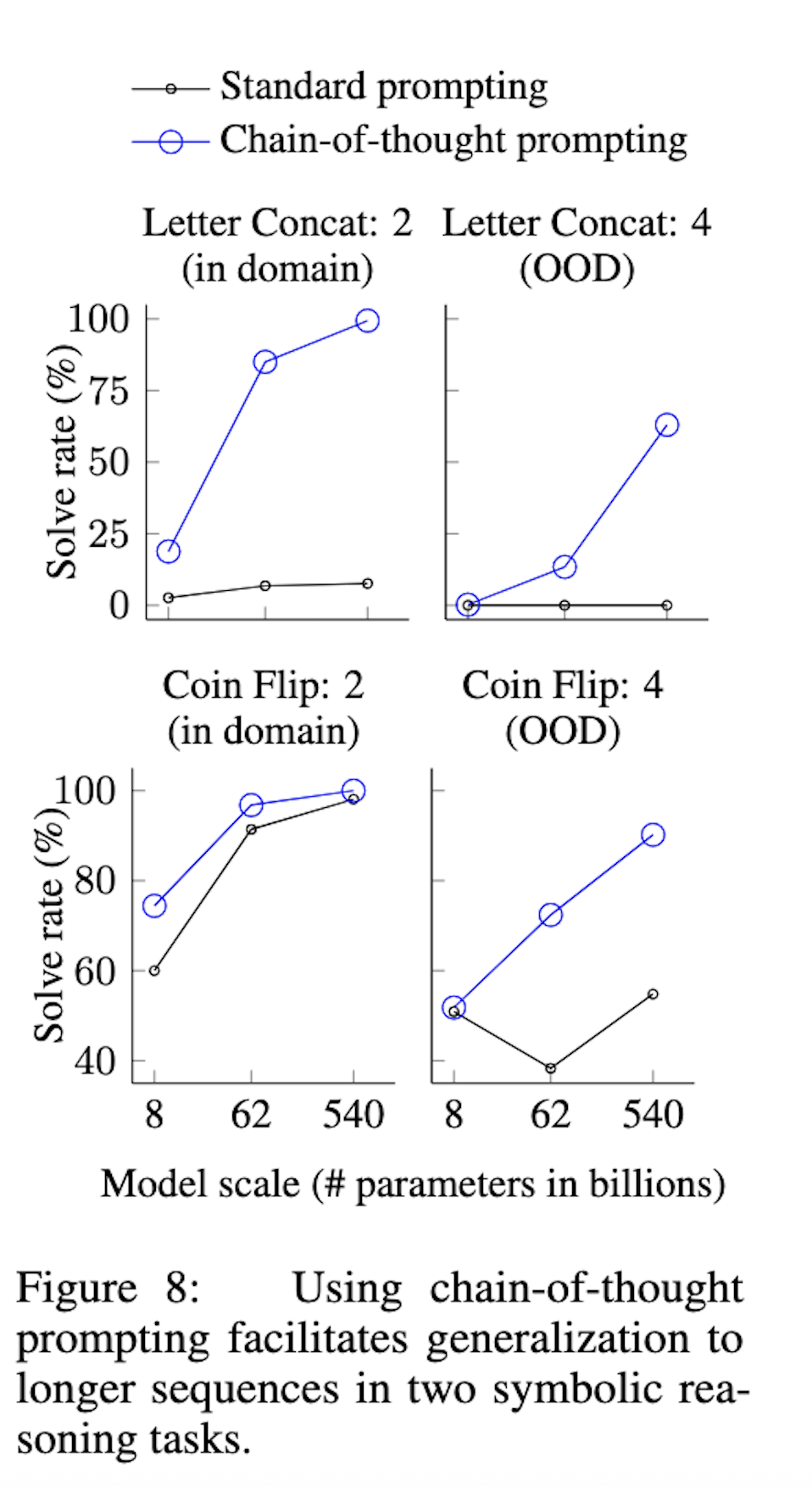
这些域内和域外评估的结果如图8所示(PaLM的结果),LaMDA的结果见附录表5。使用 PaLM 540B,思维链提示带来了接近 100% 的解决率(注意,标准提示已经能用 PaLM 540 解决抛硬币任务,但 LaMDA 137B 不行)。请注意,这些域内评估是“示例任务”,因为完美的解决方案结构已经由少样本示例中的思维链提供;模型所要做的就是用测试示例中的新符号重复相同的步骤。然而,小模型仍然失败——对这三个任务未见符号执行抽象操作的能力只在 100B 模型参数的规模上出现。
至于域外评估,标准提示在两个任务上都失败了。通过思维链提示,语言模型实现了向上的扩展曲线(尽管性能低于域内设置)。因此,对于足够规模的语言模型,思维链提示促进了超越所见思维链的长度泛化。
6. Discussion
思维链提示作为激发大型语言模型中多步推理行为的简单机制。
- 思维链提示在算术推理上大幅提高了性能,产生的改进远强于消融实验,并且对不同标注者、示例和语言模型具有鲁棒性
- 常识推理的实验强调了思维链推理的语言性质如何使其普遍适用
- 对于符号推理,思维链提示促进了向更长序列长度的域外泛化
- 在所有实验中,思维链推理仅通过提示现成的语言模型就被激发出来,并未进行微调。
思维链推理作为模型规模的结果而涌现一直是一个普遍的主题。 思维链提示似乎扩展了大型语言模型可以成功执行的任务集合——换句话说,我们的工作强调,标准提示仅提供了大型语言模型能力的下限。
至于局限性。
此外,作者还提出了本文的一些局限性,虽然文中证明了模型有利用到中间推理的信息,但是模型是否真的在推理是一个悬而未决的问题。其次,手动构建CoT成本高,质量难以保证。第三,对于推理路径,无法保证其正确性。
我们首先要说明的是,尽管思维链模拟了人类推理者的思维过程,但这并不能回答神经网络是否真的在“推理”,我们将其留作一个开放性问题。其次,尽管在少样本设置中手动用思维链增强示例的成本是最小的,但这种标注成本对于微调来说可能令人望而却步(尽管这可能会通过合成数据生成或零样本泛化来克服)。此外,无法保证推理路径的正确性,这可能导致正确和错误的答案;改进语言模型的事实生成是未来工作的一个开放方向
- 随着模型规模的增加,还期望模型理解能力能够提升多少?
- 还有哪些prompt方法可以扩展模型的解决任务范围?
笔者:
存在成本激增问题
CoT生成更多tokens: 标准回答:100 tokens CoT回答:300-500 tokens
成本:增加3-5倍论文贡献:
- 发现了规模与能力的关系
- 证明了CoT是涌现特性
- 启发了后续研究
小模型无法做的大模型突然能做
这证明了"涌现"现象的存在7. Related Work
- 使用中间步骤来解决推理问题
- 自动学习提示,向模型提供描述任务的指令,这些方法改进或增强了提示的输入部分(例如,前置到输入的指令),而本文则采取了正交的方向,用思维链增强语言模型的输出。
8. Conclusions
本文是手动构建的CoT,这种方式质量难以保证,并且效率不高,成本巨大,一个省时省力的工作是利用chatgpt等优质大语言模型自动构建CoT,当然除了构建的形式不同,CoT本身也有很多可以做的工作,比如多阶段的CoT会进一步提升模型的效果。强化学习+CoT也能进一步提高CoT的质量等。
思维链提示作为一种简单且广泛适用的方法来增强语言模型的推理能力。通过算术、符号和常识推理的实验,我们发现思维链推理是模型规模的一种涌现属性,它允许足够大的语言模型执行原本具有平坦扩展曲线的推理任务。拓宽语言模型能够执行的推理任务范围,有望激发更多关于基于语言的推理方法的工作。
- Before CoT
主要方法:微调、Few-shot简单版本关注点:模型架构、训练数据- After CoT
新方法:Prompt Engineering关注点:如何设计提示、激发模型能力Age Evolution
CoT的思维链 → ReAct的行动链 → Agent的自主链9. 参考文献
https://blog.csdn.net/HERODING23/article/details/133743439 https://zhuanlan.zhihu.com/p/631528038 https://www.cnblogs.com/xtkyxnx/p/19314051